

Startup Spotlight #14: Rise of the Machines
The battle against AI data scraping bots seems to be all but lost. If you can't beat them, join them?..

Project Overview

“The bots are already here. They’re downloading your data” — this is the warning issued by today’s startup to content-based websites, referring to bots deployed by AI developers to scrape website data for training their models.
“But we’ll help you profit from this”, the startup assures website owners.

With TollBit, site owners can set pricing for bots to access their content. Pricing can vary by content type—for example, charging more for breaking news or exclusive content—and can also differ based on the perceived financial capacity of the AI developer behind a particular bot.

The platform enables a flexible, dynamic pricing system. For instance, fees could be linked to the total number of requests from a specific bot. Pricing can also depend on keywords used in those requests.
Technically, TollBit blocks requests from all bots it recognizes via bot identifiers or server IP addresses. Only bots that provide a special token — issued after the developer agrees to terms with the website owner — are allowed access.

These authorized requests are logged, enabling the platform to generate and send invoices to AI developers automatically at the end of each billing period. The platform also monitors request frequency to ensure it doesn’t exceed agreed thresholds.

TollBit claims that integrating their platform takes just 15 minutes. From then on, it automatically manages payments from AI developers. When a bot is blocked, the platform notifies its developer, sharing the details of the restriction and providing a pre-filled agreement with access prices. The developer can simply sign and notify TollBit to resume access.
Founded last year, TollBit has already signed its first clients among website owners and secured $7 million in initial funding.
What’s the Gist?

The AI industry got itself into a proper mess last December, when The New York Times filed a lawsuit against OpenAI and Microsoft, alleging that “millions of articles” were used to train their models without permission.
By January, it was revealed that OpenAI was in negotiations with CNN, Fox, Time, and a dozen other publishers to license their content for AI training.

In February, reports surfaced that Google had struck a deal with Reddit to license its forum content for approximately $60 million. Meanwhile, Reddit’s IPO filing revealed that it had signed licensing agreements worth $203 million, with $66.4 million expected to materialize as revenue by the end of 2024.

AI algorithms are worthless without the data needed to train them. With advancements in AI, the demand for training data has grown exponentially, increasing fourfold since 2022, according to Reuters.
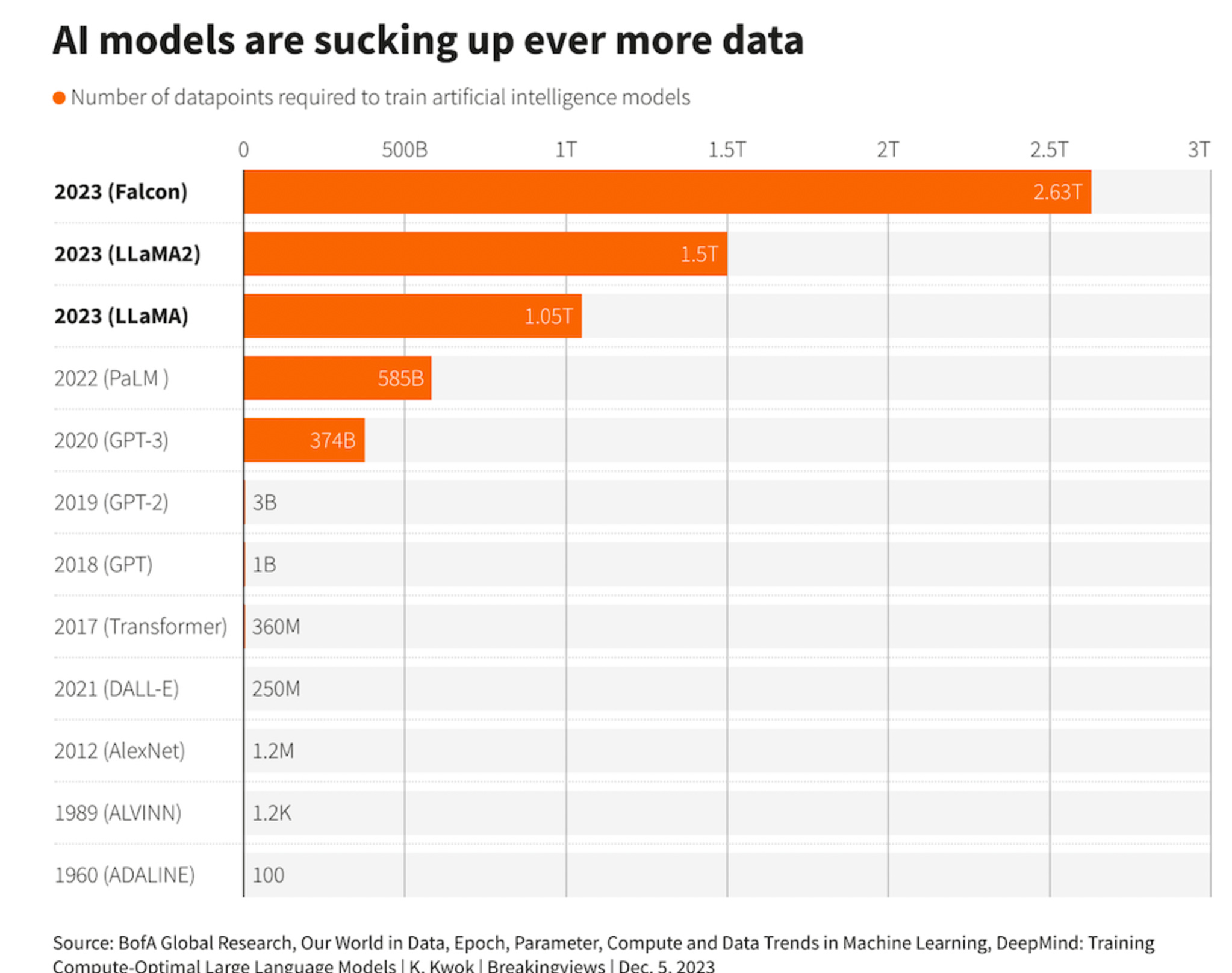
TollBit is targeting this booming and rapidly expanding market, created by the rise of AI technologies and the proliferation of AI models.
However, TollBit’s current capabilities are limited to bots scraping publicly available web pages. Yet, publicly accessible data accounts for just 4% of all data on the internet.
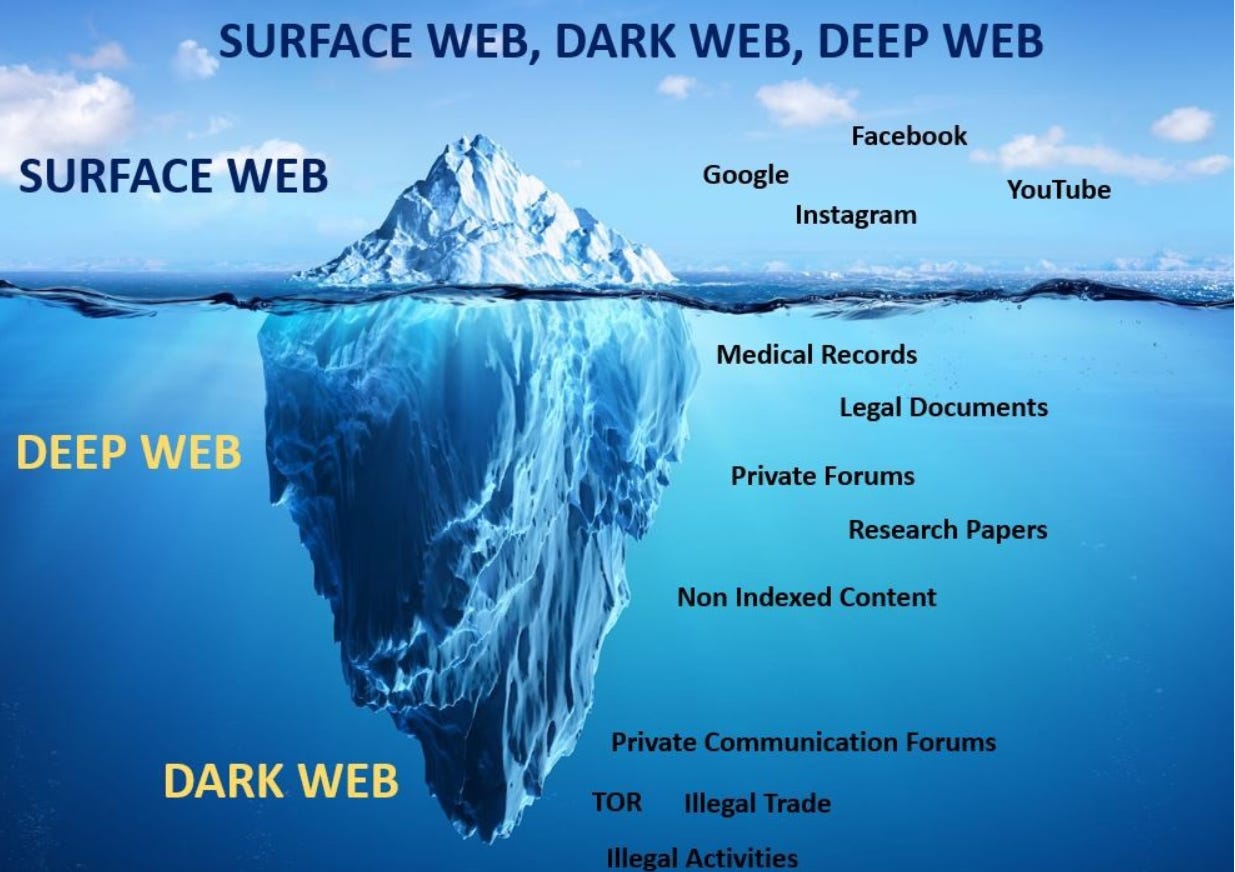
The remaining 96% is inaccessible to ordinary bots. This includes the Dark Web (6%), containing encrypted and concealed content such as private communications and illegal data, and the Deep Web (90%), which is more conventional but still out of reach for bots. Examples include password-protected pages (e.g., paywalled content) or databases requiring keyword searches, which bots struggle to navigate systematically.
While owners of subscription-based services or databases might welcome additional revenue from licensing their data, platforms must evolve to manage and monetize such content. This involves more complex technical solutions than simply blocking or granting access to public pages.
In short, 90% of the technical development required to fully unlock data licensing platforms remains ahead.
Key Takeaways
The topic of licensing content for AI training is highly relevant, given the rapid advancement of artificial intelligence and its increasing presence in every facet of our lives.
The logical direction for development is creating a user-friendly licensing platform for both content owners and AI developers. In my view, the most promising segment lies in licensing data from the Deep Web, which houses some of the most valuable and unique content, inaccessible by other means.
However, entering this space requires urgency. Each geographical market can only sustain a limited number of such platforms. Once content owners integrate with one platform, it will likely dominate, attracting more content providers and AI developers.
The key to success in promoting such platforms lies in securing agreements with providers of high-value content. In the end, AI developers will naturally gravitate toward platforms with the largest amounts of data.
Company info
TollBit
Website: https://tollbit.com/
Last funding round: $7 million, 05.03.2024
Total funds raised: $7 million over 1 round